The Database Back End
In our continuing quest to explore what goes on “under the hood” of digital humanities projects, we are moving from the front-end client-side user experience to the database “back end” on the server side, where all the data storage and information retrieval magic happens. In order to perform analysis, or present the results of our research to the public on the web, we first need to collect, categorize and store our data in a way that will give us the best combination of structure and flexibility.
You can use a simple flat spreadsheet to store enough data to power some pretty impressive applications using JavaScript alone, like using the impressive selection of tools The Knight Lab has developed for data journalism, most of which rely on Google Sheets for the backend.
In the past, students in this class used the TimelineJS framework to make a Timeline of Carleton History, and the backend was nothing more than a simple Google Sheet.
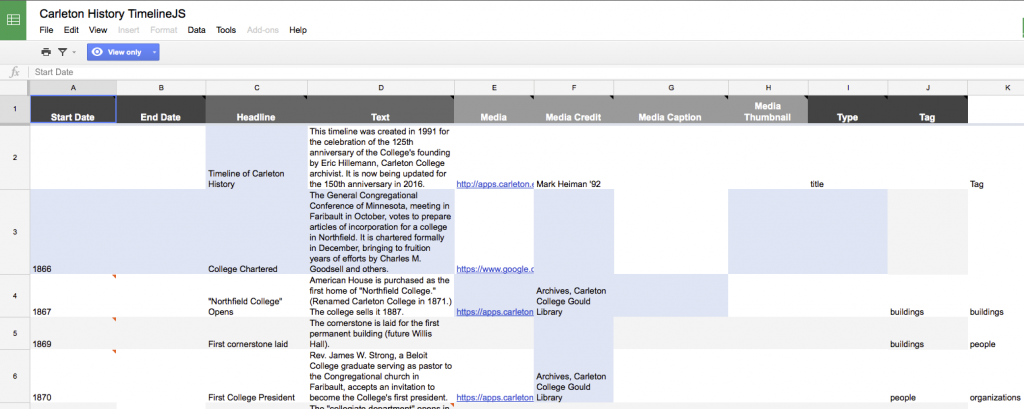
This works great for the timeline, but what if we wanted to do different things with the same data? What if we wanted to reorder our data by something other than chronology, or extract all the people or buildings, or add spatial locations? And what if we wanted to model the relationships between those elements? Our spreadsheet is just not flexible enough for this. In order to store complex data sets, we need a more sophisticated way to store it; enter the relational database.
There is a vast amount of literature out there on database design theory and practice, but the articles we read for this week provide a good starting point into the general characteristics of relational databases, and the raging debates over how to move beyond them in the brave new world of ‘big data‘ in humanities research.
The key takeaway from these debates is that “data” are not value free and neutral pieces of information. Any time we break information down and classify it into categories, we are imposing our human world view and experiences on the information, whether consciously or not. This is unavoidable, but the best way to deal with it honestly is to acknowledge our biases, document our decisions and explain our thinking at each step of the process. The resulting metadata (data about the data) are critical for successful scholarly projects, and we will discuss their importance throughout the course.
For today though, we are interested primarily in exploring how relational databases work in a typical DH project, which often shares a lot of similarities with how web applications work in general.
SIDE NOTE: In the past few years, there has been an increasing call to move away from CMSes and database-driven sites and back towards static websites. This is not pining for the bad old days, but instead relying on the increasing number of static site generators like Jekyll that let you build the site locally on your machine and push static HTML to a host rather than reacting to user requests and populating HTML with content as in most database-backed web sites. While there are many benefits to this approach, especially for fairly simple sites like blogs and those without much user interaction, there are some drawbacks to static site generators for DH projects. Knowing how databases interact with client side systems is still a valuable skill, which we will be focusing on in this course.
In-Class Exercise: Modeling Data and Metadata
We’ve spent the first few weeks of term getting a crash course in the technical infrastructure of web-based digital projects, and we have looked at how Content Management Systems like the WordPress platform this site runs on process and present data.
For most Digital Humanities projects, however, the data are going to be much more structured than blog post content. Figuring out how to model real world data in a way that let’s you answer your question or meet the goals of your project is a key part of any endeavor.
In a few weeks we are going to get a first taste by diving into the archives and beginning to gather data for our class project making 3D digitizations of objects from the college collections.
Today we are going to:
- explore the under-represented objects in various campus collections
- pick one that seems like would be a good candidate for 3d modeling or RTI and would have a good story to tell about Carleton’s history
- Add it to a class Omeka collection to think about structuring the data
Collections, Omeka, and Metadata
Metadata is essential to the organization of libraries and online collections. This is true of our Carleton College archives, which you may be using for your final projects. Our awesome librarians have set up a course guide for us that should be your starting point for entry into the archival holdings.
START HERE: Library Course Guide for DGAH 110: Hacking the Humanities
- Search through some of the resources on offer here.
- What types of primary sources are there?
- How might you model them as data?
Sometimes it can help to map your data to an established schema, such as the Dublin Core metadata schema employed by Omeka. This is what we are going to use to consider how to model the metadata about artifacts we might want to add to our collection.
Omeka
Omeka is a content management system and web publishing platform, much like WordPress or Drupal.
A few things set Omeka apart and make it a favorite for DH projects
- It was created by humanities scholars specifically for humanities projects, unlike most other platforms that have had to be hacked for humanist scholarship. Specifically, it was built by the folks at the Center for History and New Media (CHNM) at George Mason University, who also developed Zotero.
- It has robust support for metadata, by default the Dublin Core specification, a set of categories widely used by libraries, museums and cultural heritage organizations.
It’s primary use is in building collections—of documents, artifacts, images, etc.—and then organizing them into categories and allowing you to build Exhibits that tell a story from your primary sources.
An Example Project
The repository we used for last year’s class project on Carleton’s building history is one I set up through my Reclaim Hosting server:
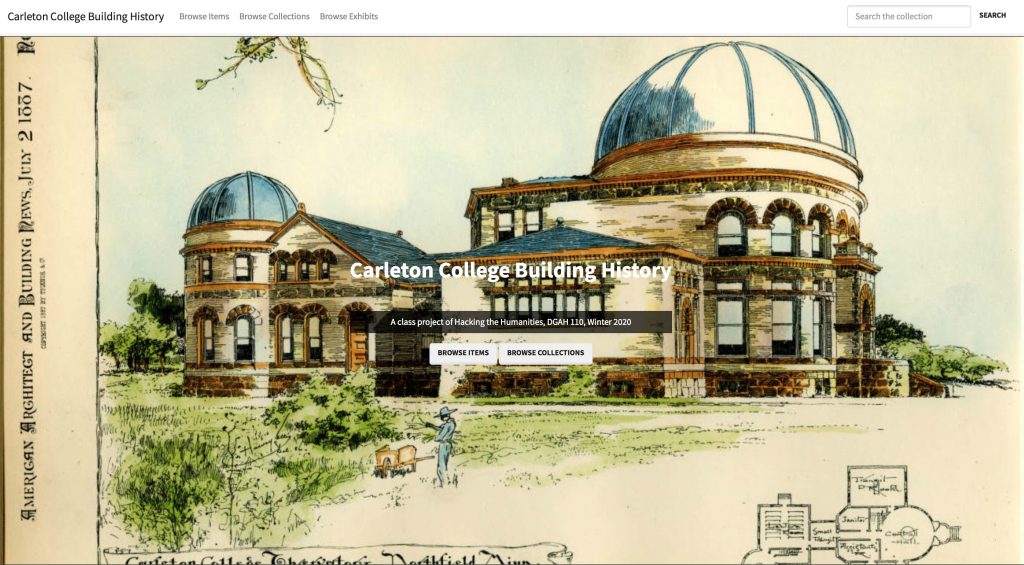
Carleton College Building History (https://campushistory.medhieval.com)
Click the link above to explore the front end of the website.
- How is the site organized?
- How is it similar to, or different than, the sites we’ve interacted with before?
- What ways are there to navigate around and find the content you desire?
I will log in and also show you the backend administrative interface. Have a look around and compare this view of the repository to the front end.
- What can you do as an admin that you couldn’t do as a user?
- How is the organization similar to our different than WordPress?
In-class Exercise: Adding items to Omeka
For this course, I have set up an Omeka site called Digital Objects of Carleton that will house our experiments with the college archives collections.
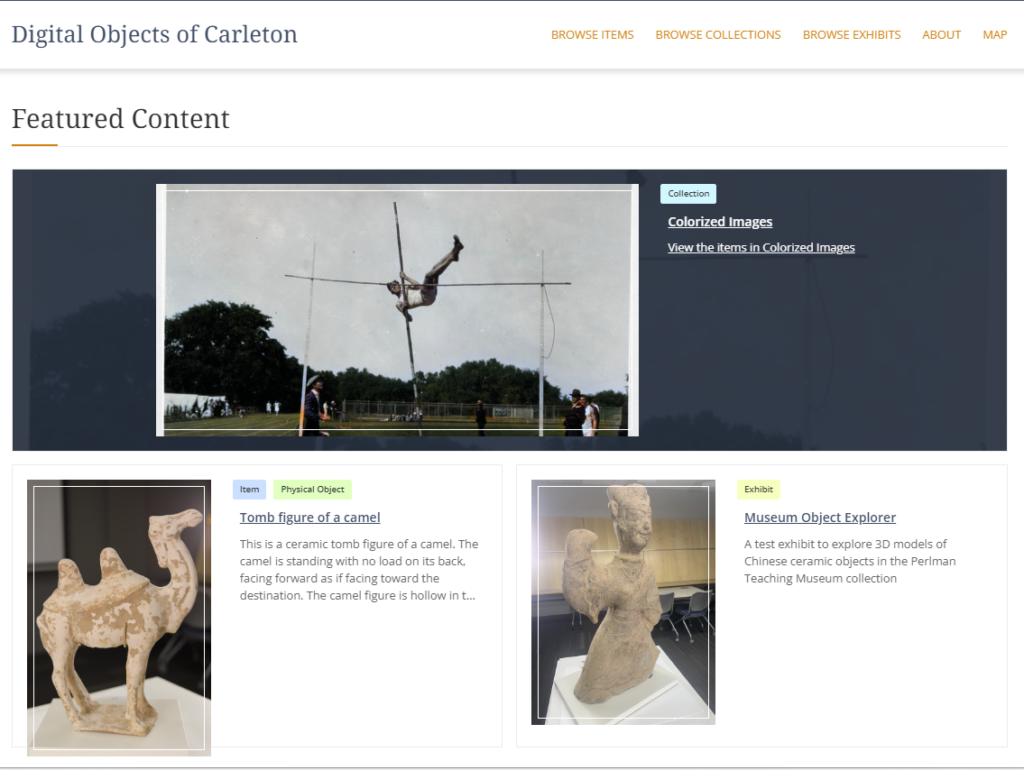
This is where we will start to build our dataset of artifacts with structured metadata about them. The archivists, special collections librarians, and museum curators have given us several lists of potentially interesting objects to use for this project.
We will start by experimenting with adding an item to Omeka
- Explore the ArchiveObjects Catalogue spreadsheet in our shared drive and find an object that may interest you
- There are multiple tabs in the Artifacts Catalog spreadsheet, with varying metadata
- The last tab “Images” has a link to a dropbox folder, where the image filenames correspond to the “Item Identifier” field in the Archive spreadsheet
- Go to the Carleton College Archives Object Collection page and search for your object identifier to see if there is more metadata for it
- Choose an item that has an image, reasonably good metadata, and is of interest to you
- Follow the instructions in the Omeka Guides linked below to get access to the site and add your item
(NB: the guides are created for a generic projects, so some of the information might not apply directly)- Activate your account
- Add an Item, making sure to also add it to the “Student Objects” Collection
- List yourself as Contributor
- For the Rights field, add the following statement
“Carleton College archives encourages the use of these materials for research, teaching, and private study according to our Terms of Use, available at https://apps.carleton.edu/digitalcollections/about/terms/” - For the Relation field, go to the Carleton College Archives Object Collection page and search for your object identifier. Add the URL of the result page to your item. For an example, see the Goodsell Dish
- Once you have an item, you can also explore how to create an exhibit with multiple items and more flexible text and image content.
REFLECTION QUESTIONS
- As you work through the Dublin Core metadata fields, what intellectual decisions are you making?
- How might your converting an object into “data” affect the results of your project?
Omeka Resources
For a good introduction to Omeka and helpful guides from its creators, see
For more overall introduction to Omeka and instructions on setting up free accounts with Omeka.net, see these two tutorials from Miriam Posner at the Programming Historian site:
Setting up your own server environment and WordPress install
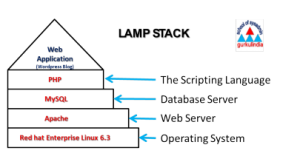
For today, we are interested primarily in exploring how relational databases work in a typical DH project, which often shares a lot of similarities with how web applications work in general. So we are going to stick with what we already know and get to know databases by exploring the backend of a WordPress site.
If you were going to do this the old fashioned way, you would need some space on a server running the LAMP stack (Linux, Apache, MySQL, and PHP) to upload, install and run a fully customizable WordPress site, but we are going to using our cPanel in Reclaim Hosting which takes care of all the system administration work for us.
I have already requested sites for each of you using the pseudonym information you requested, and Em Palencia in Academic Technology has set them all up for you.
Exploring the cPanel in class
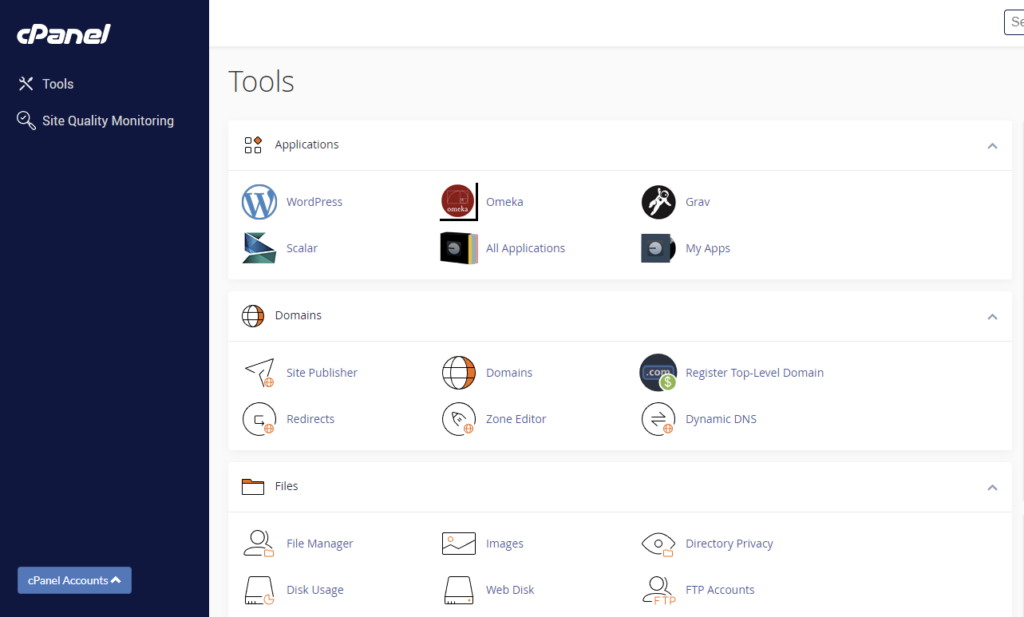
Most web applications and DH projects consist of two main components: files and a database.
The cPanel gives you access to file servers, database management, and system administration tools like one-click application installers and domain registry.
The main WordPress files you’ll interact with are the PHP template files in the theme layer, which change the look and feel of your site, and the plugins in the plugins directory, which add functionality. Check out the Resources section below for more on how to customize these.
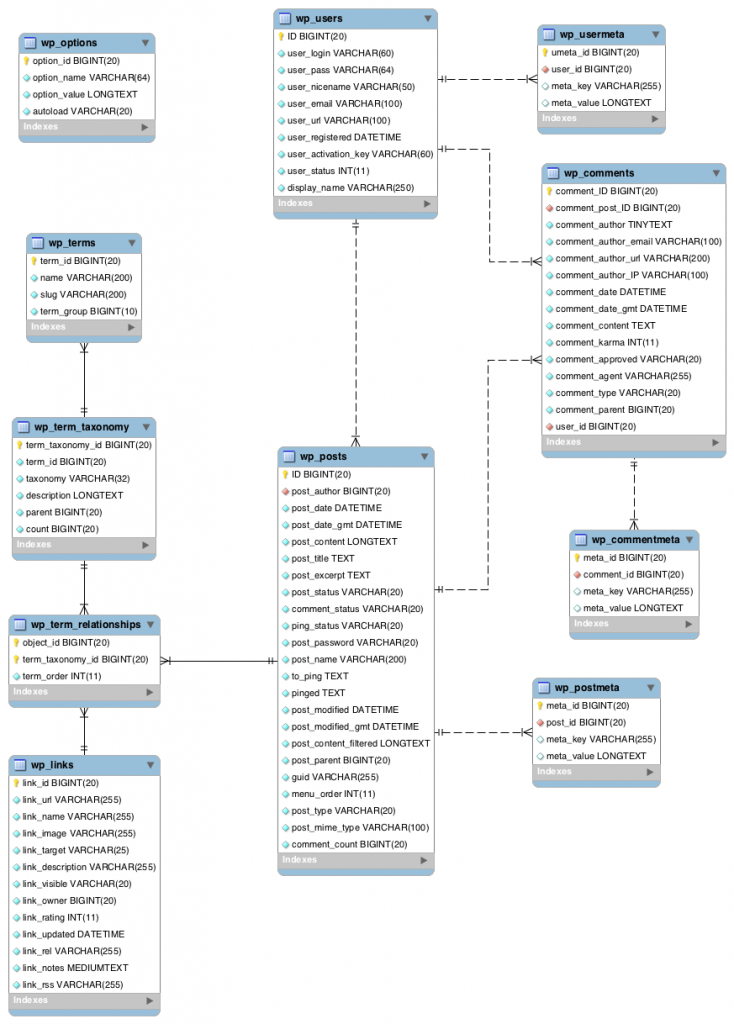
The database can be accessed via phpMyAdmin, a super helpful tool that lets you interrogate and take actions on the database without having to type SQL commands directly into a shell prompt.
- Explore the WordPress db, consulting the diagram at right,
- Can you figure out how the data and metadata of a typical post, page and comment are broken up and stored in the db.
- When you add a new plugin and a new theme to your site, ask.
- Did either change the database?
- Which one?
- Why?
As you work through the homework and get more comfortable with the server, continue to explore the guts of WordPress and ask yourself: how are the data structured, stored, and ultimately rendered in the browser? Do you understand all the component parts?
Blog Post Assignment – Your own WordPress site (due Friday)
The assignment for this week is to get to know and reflect on your new hosting environment by setting up your own WordPress site with full administrator controls:
- First, make sure you have signed the CarlSites Domain Ownership and Expectations Agreement by completing the Sign CarlSites Ownership Agreement assignment in moodle
- Install WordPress following the cPanel and WordPress Setup Instructions document here
- Spend some time setting up your personal website on your newly installed server. These are the most basic steps you should take to get your site looking like a personalized rather than a generic WordPress blog.
- Delete (or at least unpublish) all default content
- Create an “About” page (not Post) to let the world know who you are
- Write a brief bio paragraph about your background, what you are studying, your goals, etc. and post it to the site. See mine at meDHieval.com for an example.
- Protect your site from comment spam, by activitating the Akismet plugin.
- You can follow these instructions
- Choose a new theme to install and activate it
- Explore the customization options for your theme and use your DevTools skills to change at least one element of your site’s design via CSS code.
- You can add Add and Edit Additional CSS to WordPress sites in a couple of different ways, depending on the theme you chose and version you are running
Finally, write a reflective blog assignment post on THIS COURSE SITE introducing and linking to your new WordPress site and discussing your experience setting up your own WordPress install.
- What might you do with this platform?
- What benefits or drawbacks come with hosting your own website instead of signing up for a service or using a social media platform?
Post the link to your blog post in Moodle
CarlSites/WordPress Resources and Support
If you have any questions as you build your WordPress site in this class or in the future, I encourage you to reach out to Em Palencia in Academic technology. Em has also graciously shared the following resources:
- Support Documentation
- Report a Website Issue
- Meet with Digital Humanities Associates (DHAs)
- Tuesday and Wednesday evenings from 7 – 9 p.m.
- In-person drop-in at Libe 4th Floor, East Wing or via Zoom
- Contact Em in Academic Technology:
- email at@carleton.edu and ask for Em
- Em’s Office Hours